This weekend I was trying to wake my old brain up by looking and the clever and mind-bending problems from my graduate school. I have really gotten excited about Madhur Tulsi‘s Mathematical Toolkit class — as a “data scientist”/”machine learning engineer” (I sometimes wonder what these designations mean — heck I just am grateful to have been able to work on A.I. with all its challenges and contradictions for a couple of decades) I find myself treasuring the notes and exercises.
One gem that I found is the text Thirty-three Miniatures: Mathematical and Algorithmic Applications of Linear Algebra by Jiřì Matoušek. This is full of memorable tricks and insights that leverage linear algebra. While the text is mostly about proofs, I used some of the algorithms presented discussions do some Lisp programming this weekend.
I started off with the first two miniatures on Fibonacci numbers — the first presenting a fast method to get the nth Fibonacci number and the second which is probably not so fast is yet elegant in that it presents a function to compute Fibonacci numbers.
So first, I wanted to re-awaken my Lisp programming brain. Racket is definitely one of the more innovative Lisp languages to have emerged over the last 10 years. You can think of Racket as a package that provides a collection of Lisp-languages, among them standard Scheme — a paired down Lisp dialect.
The first implementation achieves 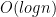



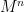

So first to see if a quick exponentiation by squaring does against the method provided in the racket math/matrix package. Here’s my quick recursive method, based on the tail recursive method in the wikipedia article
;;identity
(define one-matrix (matrix [[1 0] [0 1]]))
;;recursive exponentiation by squaring
(define (exp-by-squaring x n)
(letrec
(
[exp-by-squaring-aux
(lambda (y x n)
(cond
[(= n 0) y]
[(= n 1) (matrix* y x)]
[(= (modulo n 2) 0)
(exp-by-squaring-aux y (matrix* x x) (/ n 2))]
[else
(exp-by-squaring-aux
(matrix* y x) (matrix* x x) (/ (- n 1) 2))]))])
(exp-by-squaring-aux one-matrix x n)))
And here is a quick running time analysis
> (time (dotimes (x 1000) (exp-by-squaring (matrix [[1 1 ] [1 0]]) 100))) cpu time: 793 real time: 802 gc time: 175 > (time (dotimes (x 1000) (matrix-expt (matrix [[1 1 ] [1 0]]) 100))) cpu time: 143 real time: 144 gc time: 36 >
Looks like I’m better off with the library — although curious to know what the library implementation is.
So sticking with the matrix-expt library function:
;;;-- Miniature 1: Fibonacci Numbers, Quickly
(define one-zero-matrix (matrix [[1 0]]))
(define fib-matrix (matrix [[1 1 ] [1 0]]))
(define (fast-fib n)
;;; Fast method of computing nth fibonnaci number
(let* (
[m-expt (matrix-expt fib-matrix n)]
[idx0 0]
[idx1 1]
[prod (matrix* one-zero-matrix m-expt )]
)
(matrix-ref prod idx0 idx1 )))
Now here’s an old-school tail recursive implementation
;;; Old school fib
(define (os-fib n)
(letrec ([os-fib-helper
(lambda (n a b)
(cond
[(= n 0) b]
[else
(os-fib-helper (- n 1) b (+ a b) )]))])
(cond
[(= n 0) 0]
[(= n 1) 1]
[else
(os-fib-helper (- n 2) 1 1)])))
Now let’s look at how they compare.
> (time (dotimes (x 10000) (fast-fib 100))) cpu time: 2554 real time: 2612 gc time: 617 > (time (dotimes (x 10000) (os-fib 100))) cpu time: 41 real time: 41 gc time: 11
Wow. Maybe we’ll have to go to type checked racket to see any gains there!
Typed racket claims to get more of a boost in performance by using type hints. Here is the typed version of the fast Fibonacci
;;; -- Miniature 1: Fibonacci Numbers, Quickly (with type hints) (: one-zero-matrix (Matrix Integer)) (define one-zero-matrix (matrix [[1 0]])) (: fib-matrix (Matrix Integer)) (define fib-matrix (matrix [[1 1 ] [1 0]])) (: fast-fib (-> Integer Integer)) (define (fast-fib n) ;;; Fast method of computing nth fibonnaci number (let* ( [m-expt (matrix-expt fib-matrix n)] [idx0 : Integer 0] [idx1 : Integer 1] [prod : (Matrix Any) (matrix* one-zero-matrix m-expt )] ) (cast (matrix-ref prod idx0 idx1 ) Integer))) ;;Hacky runner to allow my bootleg benchmark (: run-fast-fib-100 (-> Integer Integer)) (define (run-fast-fib-100 n) (dotimes (x n) (fast-fib 100)) n)
> (time (run-fast-fib-100 10000)) cpu time: 689 real time: 728 gc time: 251 - : Integer 10000 > (time (run-fast-fib-100 10000)) cpu time: 672 real time: 733 gc time: 244 - : Integer 10000 > (time (run-fast-fib-100 10000)) cpu time: 704 real time: 750 gc time: 267 - : Integer 10000 > (time (dotimes (x 10000) (os-fib 100))) cpu time: 28 real time: 28 gc time: 0 > (time (dotimes (x 10000) (os-fib 100))) cpu time: 31 real time: 30 gc time: 0 > (time (dotimes (x 10000) (os-fib 100))) cpu time: 35 real time: 35 gc time: 0 >
About an order of magnitude better, but still order of magnitude worse than the iterative version though. Better off sticking with the simple iteration.
Now in the second miniature, Matoušek derives a numeric expression for the 
![F_n = 1/\sqrt{5} \left[ \right( (1 + \sqrt{5})/2 \left) ^n - \right( (1 - \sqrt{5})/2 \left) ^n \right]](https://s0.wp.com/latex.php?latex=F_n+%3D+1%2F%5Csqrt%7B5%7D+%5Cleft%5B+%5Cright%28+%281+%2B+%5Csqrt%7B5%7D%29%2F2+%5Cleft%29+%5En+-+%5Cright%28+%281+-+%5Csqrt%7B5%7D%29%2F2+%5Cleft%29+%5En+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
;;; -- Miniature 2: Fibonacci Numbers, the Formula(: root-five Real)
(define root-five (sqrt 5.0))
(define inv-root-five (/ 1.0 root-five))
(define first-tau-root (/ (+ 1.0 root-five) 2.0))
(define second-tau-root (/ (- 1.0 root-five) 2.0))
(define (fib-root n)
;;; Not so fast but fun ?
(exact-round
(* inv-root-five
(- (expt first-tau-root n) (expt second-tau-root n))))
How does compare against an “old school” iterative version?
> (time (dotimes (x 10000) (fib-root 100))) cpu time: 3 real time: 4 gc time: 0 > (time (dotimes (x 10000) (os-fib 100))) cpu time: 27 real time: 28 gc time: 0
Well, that seems to best it. At least until we get further out in the sequence, where overflow gets to be an issue
> (time (dotimes (x 10000) (fib-root 1200))) cpu time: 4 real time: 4 gc time: 0 > (time (dotimes (x 10000) (os-fib 1200))) cpu time: 1271 real time: 1419 gc time: 293 > > (time (dotimes (x 10000) (fib-root 2000))) . . exact-round: contract violation expected: rational? given: +inf.0 > (time (dotimes (x 10000) (os-fib 2000))) cpu time: 2619 real time: 2893 gc time: 725
So we’ve got constant time with the analytic solution, we might loose the better performance once we get better precision. Interesting. I’ll hold it there for now and contemplate. It’s been a nice Scheme appetizer — a feel my inner Scheme brain re-awakening.
