A few days ago I attended the talk “Sparsity, oracles and inference in high-dimensional statistics” by Sara van der Geer who is visiting Georgia Tech. The talk is described here.
But I didn’t record the talk! I had a working iPhone! I only have an after thought photo of the white board that remained after the lecture

Phones are ubiquitous and there’s nothing like a short clip that can distill some of the essence of an idea, a lecture. Maybe it’s all those “No recording devices, please!” announcements at concerts, or that my videography skills are in need of serious help.
PSA: If you think that someone is bring across some important knowledge, record it — give them their attribution, don’t steal their stuff — but you are sharing knowledge with the world!
So what was the talk about? If you do machine learning, the idea of regularization is probably familiar. L1 regularization a.k.a Least Absolute Shrinkage and Selection Operator ak.a. lasso in particular assigns a penalty on the absolute value of the predictor weights. It’s an technique that reduces the tendency to overfit to the training data. There’s a whole book on it called Statistical Learning with Sparsity that you can download for free!
The amazing thing about lasso is that it also drives the less extraneous parameters close to zero: it can reduce the number of parameters you need in your model, or it results in a model that is more sparse (that is, just remove the close-to-zero parameters from the model). This can make the model faster to compute.
The main things I picked up were that there are some bounds on the error for lasso regularization that can be expressed in terms of the number of parameters and the number of observations you have in your training set. The error should be within a constant of 

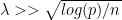
She introduced something called the compatibility constant that’s discussed further in a couple of papers [Belloni, et. a. 2014, Dalalyan 2017]. She also discussed how lasso behaves when you assume that you have noisy observations. The final lecture is September 6th at Georgia Tech on applications to inference.
Wouldn’t it have been better if I’d just recorded it though??
